Échantillonnage et intervalles de confiance
Modélisation Statistique
Dans la plupart des problèmes statistiques concrets, nous nous intéressons aux propriétés d'une grande population. Cependant, il est souvent impossible ou peu pratique de collecter des données auprès de chaque membre de cette population. Par conséquent, nous ne connaissons généralement pas les véritables paramètres de la population, tels que la moyenne de la population (\(\mu\)) ou l'écart-type de la population (\(\sigma\)).
Au lieu de cela, nous collectons des données auprès d'un sous-ensemble plus petit de la population, appelé un échantillon. Nous calculons des statistiques à partir de cet échantillon (comme la moyenne de l'échantillon \(\bar{x}\)) et les utilisons pour estimer les paramètres inconnus de la population. Ce processus est connu sous le nom d'inférence statistique. Dans cette section, nous définirons les concepts clés utilisés en échantillonnage et en estimation.
Au lieu de cela, nous collectons des données auprès d'un sous-ensemble plus petit de la population, appelé un échantillon. Nous calculons des statistiques à partir de cet échantillon (comme la moyenne de l'échantillon \(\bar{x}\)) et les utilisons pour estimer les paramètres inconnus de la population. Ce processus est connu sous le nom d'inférence statistique. Dans cette section, nous définirons les concepts clés utilisés en échantillonnage et en estimation.
Définition Échantillon
Un échantillon de taille \(n\) est constitué de \(n\) variables aléatoires indépendantes \(X_1, X_2, \dots, X_n\) qui suivent la même loi de probabilité que la population.
Définition Valeur observée
Une valeur observée, notée par un \(x\) minuscule, est une réalisation spécifique d'une variable aléatoire \(X\). C'est le nombre réel obtenu après avoir effectué une expérience ou collecté des données.
Définition Estimateur de la moyenne d'échantillon
La moyenne d'échantillon est une statistique utilisée pour estimer la moyenne de la population.
Soit \(X_1, X_2, \dots, X_n\) un échantillon aléatoire. La moyenne d'échantillon est une variable aléatoire notée \(\overline{X}_n\) :$$ \overline{X}_n = \frac{\sum_{i=1}^n X_i}{n} = \frac{X_1 + X_2 + \dots + X_n}{n} $$Pour un ensemble spécifique de valeurs observées \(x_1, x_2, \dots, x_n\), la moyenne d'échantillon calculée est notée \(\bar{x}\) :$$ \bar{x} = \frac{\sum_{i=1}^n x_i}{n} $$
Soit \(X_1, X_2, \dots, X_n\) un échantillon aléatoire. La moyenne d'échantillon est une variable aléatoire notée \(\overline{X}_n\) :$$ \overline{X}_n = \frac{\sum_{i=1}^n X_i}{n} = \frac{X_1 + X_2 + \dots + X_n}{n} $$Pour un ensemble spécifique de valeurs observées \(x_1, x_2, \dots, x_n\), la moyenne d'échantillon calculée est notée \(\bar{x}\) :$$ \bar{x} = \frac{\sum_{i=1}^n x_i}{n} $$
Proposition Estimateur sans biais de la moyenne
La moyenne d'échantillon est un estimateur sans biais de la moyenne de la population \(\mu\). Cela signifie que l'espérance de la moyenne d'échantillon est égale à la vraie moyenne de la population :$$ E[\overline{X}_n] = \mu $$
Définition Écart-type d'échantillon
L'écart-type d'échantillon, noté \(s_n\) (ou simplement \(s\)), est un estimateur de l'écart-type de la population \(\sigma\). Pour des valeurs observées \(x_1, x_2, \dots, x_n\) :$$ s_n = \sqrt{\frac{\sum_{i=1}^n (x_i - \bar{x})^2}{n-1}} $$Notez la division par \(n-1\) (correction de Bessel), qui fait que la variance d'échantillon \(s_n^2\) est un estimateur sans biais de la variance de la population.
Proposition Estimateur sans biais de la variance
La variance d'échantillon \(S_n^2 = \frac{\sum (X_i - \overline{X}_n)^2}{n-1}\) est un estimateur sans biais de la variance de la population \(\sigma^2\) :$$ E[S_n^2] = \sigma^2 $$
Exemple Enquête : Aimez-vous les mathématiques ?
Pour une enquête éducative, 10 étudiants évaluent à quel point ils aiment les mathématiques sur une échelle de 0 à 10.Soient \(X_1, X_2, \dots, X_{10}\) les variables aléatoires représentant l'évaluation de chaque étudiant.Les valeurs observées sont : \(x = \{2, 4, 0, 9, 10, 3, 7, 2, 8, 9\}\).
- Moyenne de l'échantillon : $$ \bar{x} = \frac{2+4+0+9+10+3+7+2+8+9}{10} = \frac{54}{10} = 5,4 $$
- Écart-type de l'échantillon : En utilisant une calculatrice (statistiques de liste) : $$ s_{n} \approx 3,50 $$
Intervalles de confiance pour les moyennes avec variance connue
Une estimation ponctuelle, comme la moyenne d'échantillon \(\bar{x}\), fournit une valeur unique comme estimation du paramètre de la population. Cependant, elle ne nous dit pas à quel point cette estimation est précise. En raison de la variabilité d'échantillonnage, \(\bar{x}\) est rarement exactement égale à la vraie moyenne \(\mu\).
Pour remédier à cela, nous utilisons un intervalle de confiance. Un intervalle de confiance fournit une plage de valeurs à l'intérieur de laquelle nous nous attendons à ce que le vrai paramètre de la population se trouve, avec un certain niveau de confiance (probabilité). Dans cette section, nous supposons que la variance de la population \(\sigma^2\) est connue, ce qui nous permet d'utiliser la loi normale standard (\(Z\)).
Pour remédier à cela, nous utilisons un intervalle de confiance. Un intervalle de confiance fournit une plage de valeurs à l'intérieur de laquelle nous nous attendons à ce que le vrai paramètre de la population se trouve, avec un certain niveau de confiance (probabilité). Dans cette section, nous supposons que la variance de la population \(\sigma^2\) est connue, ce qui nous permet d'utiliser la loi normale standard (\(Z\)).
Proposition Intervalle de probabilité
Supposons que l'on prenne un échantillon de taille \(n\) d'une population de moyenne \(\mu\) et d'écart-type \(\sigma\), et que \(n\) soit suffisamment grand (typiquement \(n \ge 30\) pour que le théorème central limite s'applique). Alors$$ P\left(\overline{X}_n - 1,96 \frac{\sigma}{\sqrt{n}} \leqslant \mu \leqslant \overline{X}_n + 1,96 \frac{\sigma}{\sqrt{n}}\right) = 0,95. $$
Puisque \(n\) est grand, le théorème central limite s'applique. La distribution d'échantillonnage de la moyenne \(\overline{X}_n\) est approximativement normale avec une moyenne \(\mu\) et un écart-type \(\dfrac{\sigma}{\sqrt{n}}\).
La variable standardisée \(Z\) suit une loi normale standard :$$ Z = \frac{\overline{X}_n - \mu}{\sigma/\sqrt{n}} \sim N(0, 1). $$Pour un niveau de confiance de \(95\pourcent\), nous cherchons la valeur critique \(z\) telle que \(P(-z \leqslant Z \leqslant z) = 0,95\).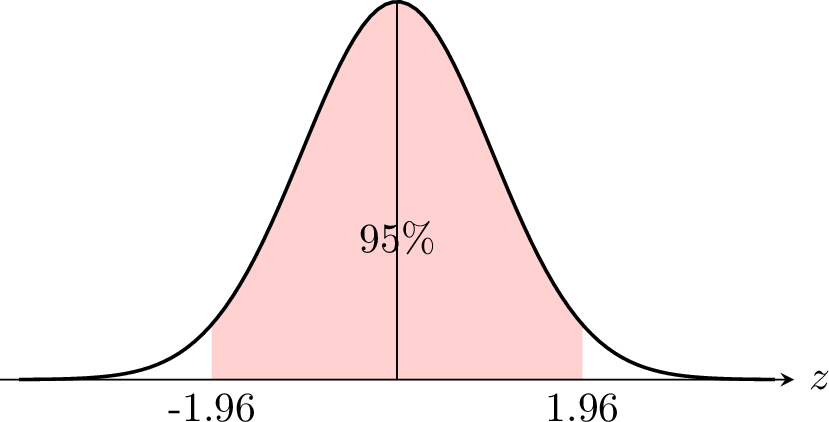
La variable standardisée \(Z\) suit une loi normale standard :$$ Z = \frac{\overline{X}_n - \mu}{\sigma/\sqrt{n}} \sim N(0, 1). $$Pour un niveau de confiance de \(95\pourcent\), nous cherchons la valeur critique \(z\) telle que \(P(-z \leqslant Z \leqslant z) = 0,95\).
La proposition ci-dessus nous donne un énoncé de probabilité sur la moyenne d'échantillon aléatoire \(\overline{X}_n\) et sur l'intervalle aléatoire construit à partir d'elle. Le paramètre \(\mu\) est fixé (mais inconnu) ; ce qui est aléatoire, c'est l'intervalle lui-même.
Pour calculer un intervalle de confiance concret, nous estimons cet intervalle de probabilité en remplaçant la variable aléatoire \(\overline{X}_n\) par la moyenne d'échantillon observée \(\bar{x}\). Ainsi, l'intervalle de confiance que nous obtenons est une estimation de l'intervalle théorique.
Pour calculer un intervalle de confiance concret, nous estimons cet intervalle de probabilité en remplaçant la variable aléatoire \(\overline{X}_n\) par la moyenne d'échantillon observée \(\bar{x}\). Ainsi, l'intervalle de confiance que nous obtenons est une estimation de l'intervalle théorique.
Méthode Calcul de l'intervalle de confiance (Moyenne)
- Identifier les statistiques : Trouver la moyenne d'échantillon \(\bar{x}\), l'écart-type de la population connu \(\sigma\) et la taille de l'échantillon \(n\).
- Trouver le score \(z\) : Déterminer \(z\) selon le niveau de confiance (1,645 pour 90\(\pourcent\), 1,96 pour 95\(\pourcent\), 2,576 pour 99\(\pourcent\)).
- Calculer la marge d'erreur : \(E = z \dfrac{\sigma}{\sqrt{n}}\).
- Écrire l'intervalle : \([\bar{x} - E, \bar{x} + E]\).
Exemple
Un échantillon de 60 lapins a été prélevé dans une forêt. Le poids moyen de l'échantillon des lapins était de 950 grammes. Supposons que l'écart-type de la population soit connu et égal à \(\sigma = 200\) grammes.
Trouvez l'intervalle de confiance à \(95\pourcent\) pour le poids moyen de la population.
Trouvez l'intervalle de confiance à \(95\pourcent\) pour le poids moyen de la population.
- Statistiques : \(n=60\), \(\bar{x}=950\) et \(\sigma=200\).
- Score \(z\) : Pour \(95\pourcent\), \(z = 1,96\).
- Marge d'erreur : $$ E = 1,96 \times \frac{200}{\sqrt{60}} \approx 1,96 \times 25,82 \approx 50,6. $$
- Intervalle : $$ [950 - 50,6 ; \ 950 + 50,6] = [899,4 ; 1000,6]. $$
Intervalles de confiance pour les moyennes avec variance inconnue
Dans la plupart des situations pratiques, l'écart-type de la population \(\sigma\) est inconnu. Nous ne pouvons pas utiliser directement la loi normale (\(Z\)) avec une valeur connue de \(\sigma\), car nous devons estimer \(\sigma\) en utilisant l'écart-type d'échantillon \(s_n\).
En théorie, lorsque la population est normale et que \(\sigma\) est inconnu, la distribution exacte de$$ \frac{\overline{X}_n - \mu}{S_n/\sqrt{n}} $$est une loi de Student (t) à \(n-1\) degrés de liberté. Pour des échantillons de grande taille (par exemple \(n \ge 30\)), la loi de Student est très proche de la loi normale standard. Dans ce cours, pour \(n\) grand, nous approcherons en utilisant les mêmes valeurs de \(z\) qu'auparavant et en remplaçant \(\sigma\) par \(s_n\).
En théorie, lorsque la population est normale et que \(\sigma\) est inconnu, la distribution exacte de$$ \frac{\overline{X}_n - \mu}{S_n/\sqrt{n}} $$est une loi de Student (t) à \(n-1\) degrés de liberté. Pour des échantillons de grande taille (par exemple \(n \ge 30\)), la loi de Student est très proche de la loi normale standard. Dans ce cours, pour \(n\) grand, nous approcherons en utilisant les mêmes valeurs de \(z\) qu'auparavant et en remplaçant \(\sigma\) par \(s_n\).
Méthode Calcul de l'intervalle de confiance (\(\sigma\) inconnu\(\virgule\) \(n\) grand)
- Identifier les statistiques : Trouver la moyenne d'échantillon \(\bar{x}\), l'écart-type d'échantillon \(s_n\) (comme estimation de \(\sigma\)) et la taille de l'échantillon \(n\).
- Trouver le score \(z\) : Déterminer \(z\) selon le niveau de confiance (1,645 pour 90\(\pourcent\), 1,96 pour 95\(\pourcent\), 2,576 pour 99\(\pourcent\)), en supposant que \(n\) est grand.
- Calculer la marge d'erreur : \(E = z \dfrac{s_n}{\sqrt{n}}\).
- Écrire l'intervalle : \([\bar{x} - E, \bar{x} + E]\).
Exemple
Un économiste étudiant les coûts du carburant veut estimer le prix moyen de l'essence dans son État. Il prend un échantillon aléatoire de 40 stations-service et trouve un prix moyen de \(\bar{x} = 1,29\dollar\) avec un écart-type d'échantillon de \(s_n = 0,10\dollar\).
Trouvez l'intervalle de confiance à \(95\pourcent\) pour la moyenne de la population.
Trouvez l'intervalle de confiance à \(95\pourcent\) pour la moyenne de la population.
- Statistiques : \(n=40\), \(\bar{x}=1,29\) et \(s_n=0,10\). (Puisque \(n \ge 30\), on approxime \(\sigma \approx s_n\).)
- Score \(z\) : Pour \(95\pourcent\), \(z = 1,96\).
- Marge d'erreur : $$ E = 1,96 \times \frac{0,10}{\sqrt{40}} \approx 1,96 \times 0,0158 \approx 0,031. $$
- Intervalle : $$ [1,29 - 0,031 ; \ 1,29 + 0,031] = [1,259 ; 1,321]. $$
Intervalles de confiance pour les proportions
Lorsque l'on traite des données catégorielles (comme le vote pour le candidat A ou B), on s'intéresse à la proportion de la population \(p\) (le vrai pourcentage de voix). Puisque l'on ne peut pas interroger tout le monde, on estime \(p\) en utilisant la proportion d'échantillon \(\hat{p}\).
Chaque réponse individuelle (succès/échec) est une variable aléatoire de Bernoulli de variance \(p(1-p)\) et d'écart-type \(\sigma = \sqrt{p(1-p)}\).
Comme la proportion d'échantillon \(\hat{p}\) est la moyenne de \(n\) variables de Bernoulli, son écart-type est \(\dfrac{\sigma}{\sqrt{n}}\).
Par conséquent, l'erreur type pour une proportion est$$ \sqrt{\frac{p(1-p)}{n}}, $$que nous estimons en utilisant les données de l'échantillon par$$ \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}. $$Cette approximation normale est valable lorsque la taille de l'échantillon est suffisamment grande, typiquement lorsque \(n\hat{p} \ge 5\) et \(n(1-\hat{p}) \ge 5\).
Chaque réponse individuelle (succès/échec) est une variable aléatoire de Bernoulli de variance \(p(1-p)\) et d'écart-type \(\sigma = \sqrt{p(1-p)}\).
Comme la proportion d'échantillon \(\hat{p}\) est la moyenne de \(n\) variables de Bernoulli, son écart-type est \(\dfrac{\sigma}{\sqrt{n}}\).
Par conséquent, l'erreur type pour une proportion est$$ \sqrt{\frac{p(1-p)}{n}}, $$que nous estimons en utilisant les données de l'échantillon par$$ \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}. $$Cette approximation normale est valable lorsque la taille de l'échantillon est suffisamment grande, typiquement lorsque \(n\hat{p} \ge 5\) et \(n(1-\hat{p}) \ge 5\).
Méthode Construire l'intervalle
- Calculer la proportion d'échantillon : \(\hat{p} = \dfrac{\text{Succès}}{\text{Total Échantillon}}\).
- Trouver le score \(z\) : Déterminer \(z\) selon le niveau de confiance (1,645 pour 90\(\pourcent\), 1,96 pour 95\(\pourcent\), 2,576 pour 99\(\pourcent\)).
- Calculer la marge d'erreur : \(E = z \sqrt{\dfrac{\hat{p}(1-\hat{p})}{n}}\).
- Écrire l'intervalle : \([\hat{p} - E, \hat{p} + E]\).
Exemple
Un institut de sondage interroge \(n=1000\) électeurs au hasard avant une élection. 520 personnes disent qu'elles voteront pour le candidat A.
- Calculez la proportion d'échantillon \(\hat{p}\).
- Construisez un intervalle de confiance à \(95\pourcent\) pour la vraie proportion d'électeurs soutenant le candidat A.
- Sur la base de cet intervalle, le candidat A peut-il être certain de gagner (obtenir plus de \(50\pourcent\) des voix) ? Expliquez.
- \(\hat{p} = \dfrac{520}{1000} = 0,52\).
- En utilisant le niveau de confiance de 95\(\pourcent\) (\(z=1,96\)) : $$ \begin{aligned} E &= 1,96 \sqrt{\frac{0,52(1-0,52)}{1000}} \\ &= 1,96 \sqrt{\frac{0,52 \times 0,48}{1000}} \\ &= 1,96 \sqrt{0,0002496} \\ &= 1,96(0,0158) \\ &\approx 0,031. \end{aligned} $$ L'intervalle de confiance est : $$ [0,52 - 0,031 ; \ 0,52 + 0,031] = [0,489 ; 0,551] $$ (Ou \(48,9\pourcent\) à \(55,1\pourcent\)).
- Non. Bien que la proportion de l'échantillon soit de \(52\pourcent\), l'intervalle inclut des valeurs inférieures à \(0,5\) (par exemple \(0,489\)). Par conséquent, il est plausible que la vraie proportion soit inférieure à \(50\pourcent\). L'élection est trop serrée pour conclure avec certitude.
Tests d'hypothèses utilisant des intervalles de confiance
Les intervalles de confiance peuvent être utilisés comme un outil pour les tests d'hypothèses. Si quelqu'un affirme que la moyenne de la population vaut une valeur spécifique (\(\mu_H\)), nous pouvons vérifier si cette valeur est ``plausible'' en voyant si elle tombe dans notre intervalle de confiance calculé.
Pour un test bilatéral au niveau de signification \(\alpha\) (par exemple \(5\pourcent\)), l'intervalle de confiance de niveau \((1-\alpha)\) (par exemple \(95\pourcent\)) conduit à la même décision que le test d'hypothèses \(H_0 : \mu = \mu_H\) contre \(H_1 : \mu \neq \mu_H\).
Pour un test bilatéral au niveau de signification \(\alpha\) (par exemple \(5\pourcent\)), l'intervalle de confiance de niveau \((1-\alpha)\) (par exemple \(95\pourcent\)) conduit à la même décision que le test d'hypothèses \(H_0 : \mu = \mu_H\) contre \(H_1 : \mu \neq \mu_H\).
Méthode Test d'hypothèse avec IC
Pour tester une affirmation selon laquelle la moyenne de la population est \(\mu_H\) à un niveau de signification \(\alpha\) (par ex.\ \(5\pourcent\)) :
- Construire l'intervalle de confiance correspondant de niveau \((1-\alpha)\) (par ex.\ \(95\pourcent\)) pour \(\mu\) à partir des données de l'échantillon.
- Règle de décision :
- Si \(\mu_H\) est à l'intérieur de l'intervalle, nous ne rejetons pas l'affirmation (l'affirmation est plausible).
- Si \(\mu_H\) est à l'extérieur de l'intervalle, nous rejetons l'affirmation (le résultat est statistiquement significatif au niveau \(\alpha\)).
Exemple
Une machine est réglée pour remplir des bouteilles de jus avec une moyenne de \(50 \mathrm{cl}\). Un inspecteur du contrôle qualité prélève un échantillon de 36 bouteilles et trouve un contenu moyen de \(48,5 \mathrm{cl}\) avec un écart-type de \(5 \mathrm{cl}\).
Testez l'affirmation selon laquelle la moyenne de la machine est toujours de \(50 \mathrm{cl}\) au niveau de signification de 5\(\pourcent\), en utilisant un intervalle de confiance à \(95\pourcent\) pour \(\mu\).
Testez l'affirmation selon laquelle la moyenne de la machine est toujours de \(50 \mathrm{cl}\) au niveau de signification de 5\(\pourcent\), en utilisant un intervalle de confiance à \(95\pourcent\) pour \(\mu\).
Taille de l'échantillon \(n=36\), \(\bar{x}=48,5\), \(s_n=5\). Comme \(n\) est suffisamment grand, nous utilisons l'approximation normale avec \(z=1,96\).
Nous construisons l'intervalle de confiance à \(95\pourcent\) pour la vraie moyenne \(\mu\) :$$ \begin{aligned}IC &= 48,5 \pm 1,96 \frac{5}{\sqrt{36}} \\ &= 48,5 \pm 1,96 \left(\frac{5}{6}\right) \\ &= 48,5 \pm 1,633 \\ &= [46,87 ; 50,13].\end{aligned} $$Conclusion : La valeur revendiquée \(\mu_H = 50\) se situe à l'intérieur de l'intervalle de confiance \([46,87 ; 50,13]\). Par conséquent, nous ne rejetons pas l'affirmation au niveau de 5\(\pourcent\). Il n'y a pas assez de preuves pour dire que la machine fonctionne mal sur la base de cet échantillon.
Nous construisons l'intervalle de confiance à \(95\pourcent\) pour la vraie moyenne \(\mu\) :$$ \begin{aligned}IC &= 48,5 \pm 1,96 \frac{5}{\sqrt{36}} \\ &= 48,5 \pm 1,96 \left(\frac{5}{6}\right) \\ &= 48,5 \pm 1,633 \\ &= [46,87 ; 50,13].\end{aligned} $$Conclusion : La valeur revendiquée \(\mu_H = 50\) se situe à l'intérieur de l'intervalle de confiance \([46,87 ; 50,13]\). Par conséquent, nous ne rejetons pas l'affirmation au niveau de 5\(\pourcent\). Il n'y a pas assez de preuves pour dire que la machine fonctionne mal sur la base de cet échantillon.
Détermination de la taille de l'échantillon
Avant de mener une étude, les chercheurs ont souvent besoin de savoir combien de points de données collecter pour atteindre un niveau de précision souhaité. En manipulant la formule de la marge d'erreur, nous pouvons déterminer la taille d'échantillon requise \(n\) (par exemple, pour estimer une moyenne avec un écart-type \(\sigma\) connu).
Proposition Formule de la taille de l'échantillon
Pour estimer une moyenne de population avec une marge d'erreur \(E\) et un niveau de confiance spécifique (correspondant à \(z\)), lorsque \(\sigma\) est connu, la taille d'échantillon requise est :$$ n = \left( \frac{z \sigma}{E} \right)^2. $$Note : Puisque \(n\) doit être un entier, il faut toujours arrondir à l'entier supérieur.
En partant de la définition de la marge d'erreur :$$ E = z \frac{\sigma}{\sqrt{n}} $$on réarrange :$$ \sqrt{n} E = z \sigma $$$$ \sqrt{n} = \frac{z \sigma}{E} $$$$ n = \left( \frac{z \sigma}{E} \right)^2. $$
Exemple
Une société de marketing veut estimer les dépenses moyennes des étudiants pendant les vacances de printemps. Elle veut que l'estimation soit à moins de \(120\dollar\) de la vraie moyenne avec une confiance de \(90\pourcent\). Une étude pilote suggère que l'écart-type est \(\sigma = 400\dollar\). Combien d'étudiants doivent être échantillonnés ?
Données :
Résultat : Un échantillon de taille \(n=31\) est requis.
- Marge d'erreur \(E = 120\)
- Écart-type \(\sigma = 400\)
- Niveau de confiance \(90\pourcent \implies z \approx 1,645\) (d'après la calculatrice ou les tables)
Résultat : Un échantillon de taille \(n=31\) est requis.